Building a Fully Autonomous Crypto Intelligence Engine
Autonomous data collection, analysis, and archival framework — part data warehouse, part AI-powered research engine.

What if you could capture the entire internet footprint of every crypto project — their websites, social channels, whitepapers, conversations, and evolution over time — and make it all queryable, analyzable, and permanent?
That’s exactly what this project sets out to do.
(Another code base is handling blockchain data ingestion and storage.)
A Complete Digital Memory for Crypto
At its core, this isn’t just another blockchain data scraper.
It’s an autonomous data collection, analysis, and archival framework — part data warehouse, part AI-powered research engine.
It ingests everything about a blockchain project, processes millions of data points, and even archives websites in WARC format for long-term replay.
Think of it as Wayback Machine meets AI research platform — purpose-built for blockchain data.
The Architecture
The system runs as a modular microservice environment orchestrated through Docker, ensuring reproducibility and fault isolation.
- Language: Python 3.10+ with SQLAlchemy ORM
- Databases: PostgreSQL (primary), Redis (cache)
- AI Stack: Ollama for local LLM inference (with OpenAI & Anthropic options)
- Storage: WARC 1.1 archival (local/S3/Azure backends)
Every dataset, every crawl, every snapshot is timestamped and versioned.
Key Components
-
Data Collection Layer (
src/collectors/)- LiveCoinWatch API: Primary data source (10K requests/day limit)
- Rate limiting with retry logic and API usage tracking
- Collects 52K+ crypto projects with market data & social links
-
Scrapers (
src/scrapers/)- Website, whitepaper (PDF), Reddit, Medium, YouTube
- Intelligent content extraction with fallback strategies
- Respectful crawling with rate limiting
-
LLM Analysis (
src/analyzers/)- Website, whitepaper, Reddit, Twitter, Telegram, Medium, YouTube analyzers
- Structured output for technology, tokenomics, team, risks
- Supports Ollama (local), OpenAI, Anthropic
-
Web Archival System (
src/archival/) — 80% Complete- WARC 1.1 format storage with multi-backend support (Local / S3 / Azure)
- Three crawler engines: Browsertrix (Docker + JS), Simple HTTP, Brozzler
- Multi-level change detection (content / structure / resources / pages)
- CDX indexing with SURT transformation
- CLI tools for manual operations
- Remaining: Replay UI (
pywb), scheduling daemon, pipeline integration
-
Pipelines (
src/pipelines/)- Content analysis pipeline: discovery → scraping → LLM → storage
- Multi-stage processing with comprehensive error handling
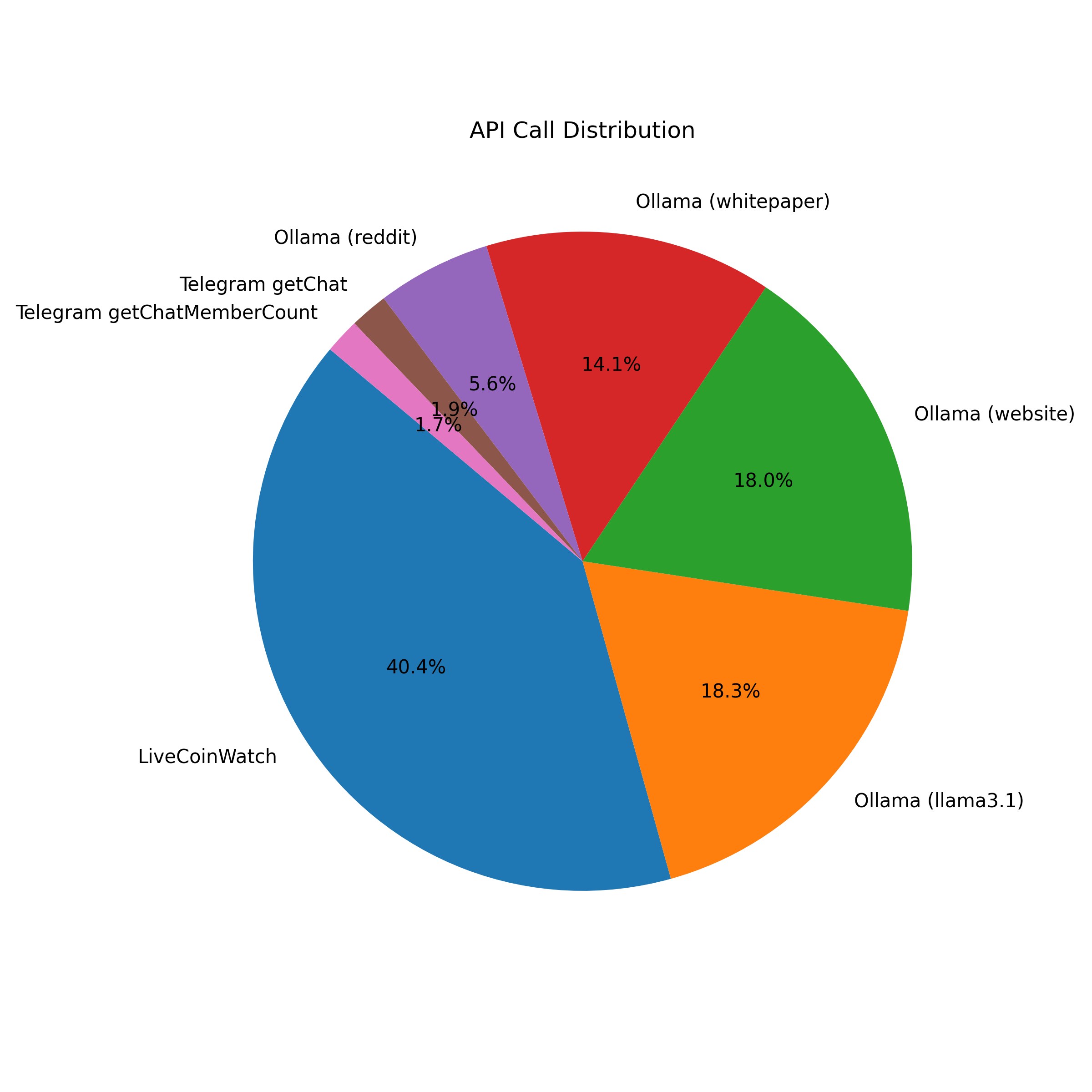
Over 53,000 Crypto Projects Indexed
The current live database tracks 53,057 projects, 181,528 links, and 2.5 million change events.
It’s a massive evolving record of the blockchain web.
| Category | Count |
|---|---|
| Projects | 53,057 |
| Project Links | 181,528 |
| Whitepapers | 22,316 |
| LLM Analyses (last 30 days) | 17,332 |
| Changes Tracked | 2.5M+ |
Database Composition
To understand what powers this intelligence, here’s how the database space breaks down:
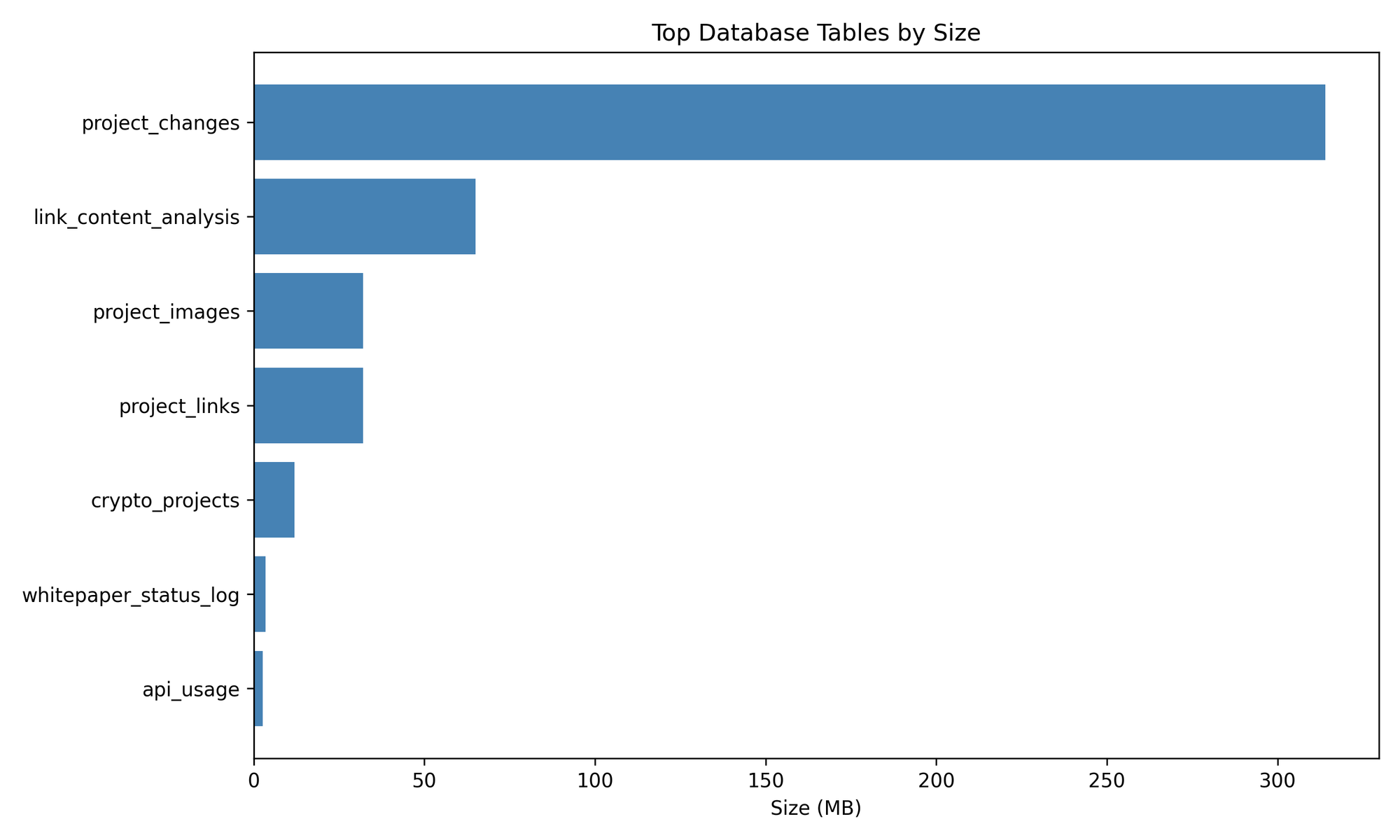
The project_changes table dominates — storing 314 MB of historical deltas, enabling time-travel-level insight into project evolution.
Link Distribution & Analysis Completion
Your data pipeline actively monitors and analyzes every social and content source.
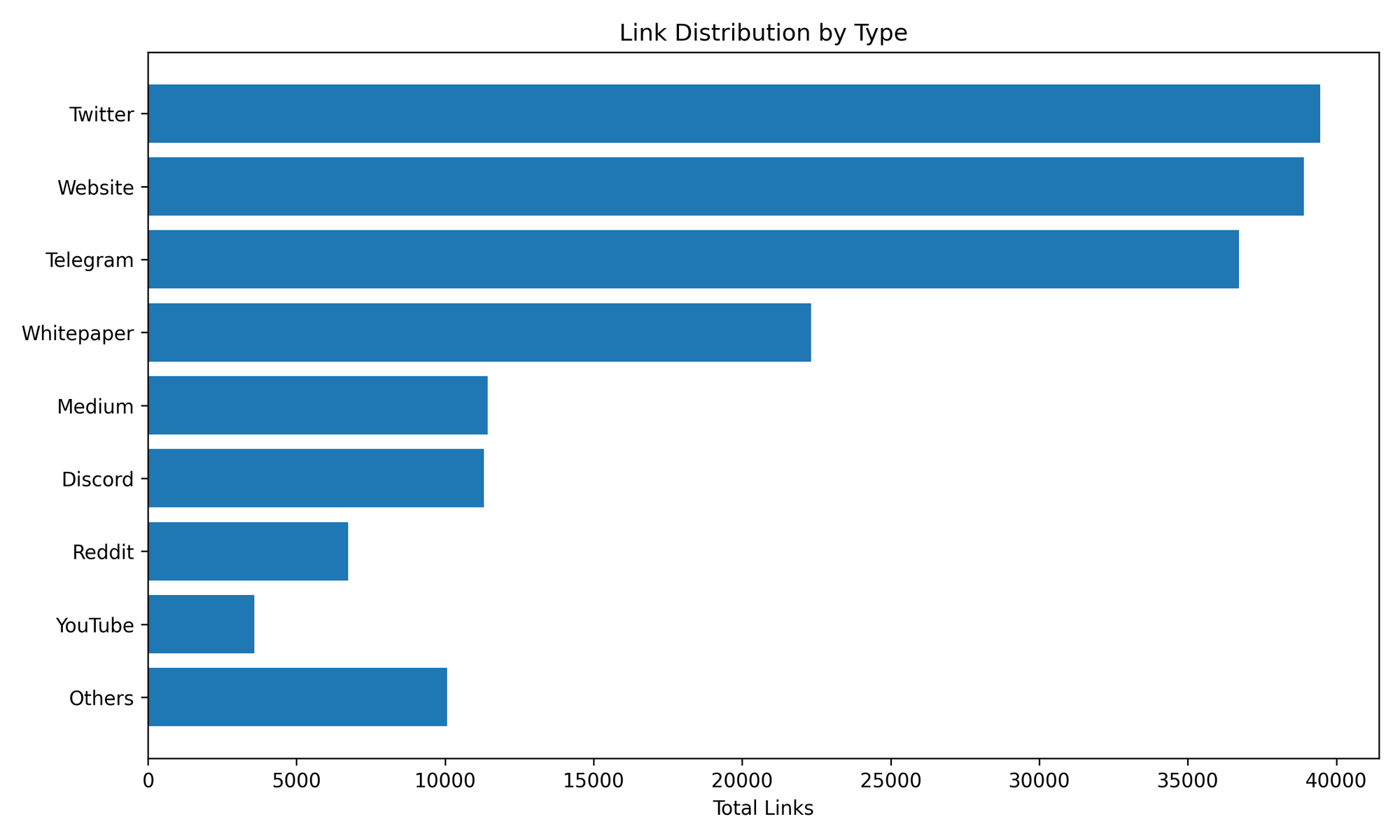
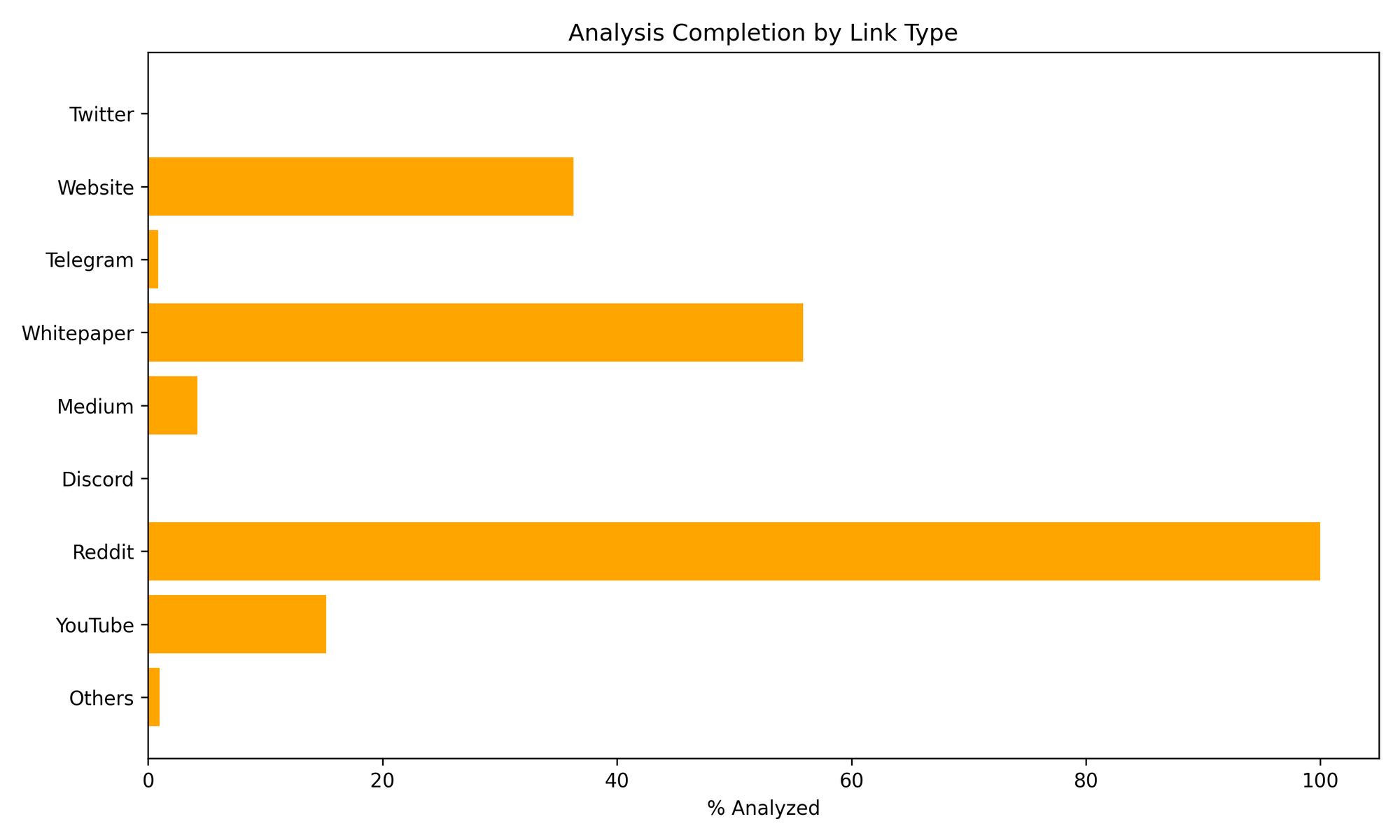
While the raw link data is vast, not all sources are equally processed yet. Here’s how far along each link type is in the AI analysis pipeline:
For even deeper visibility, this view separates total vs analyzed link volumes:
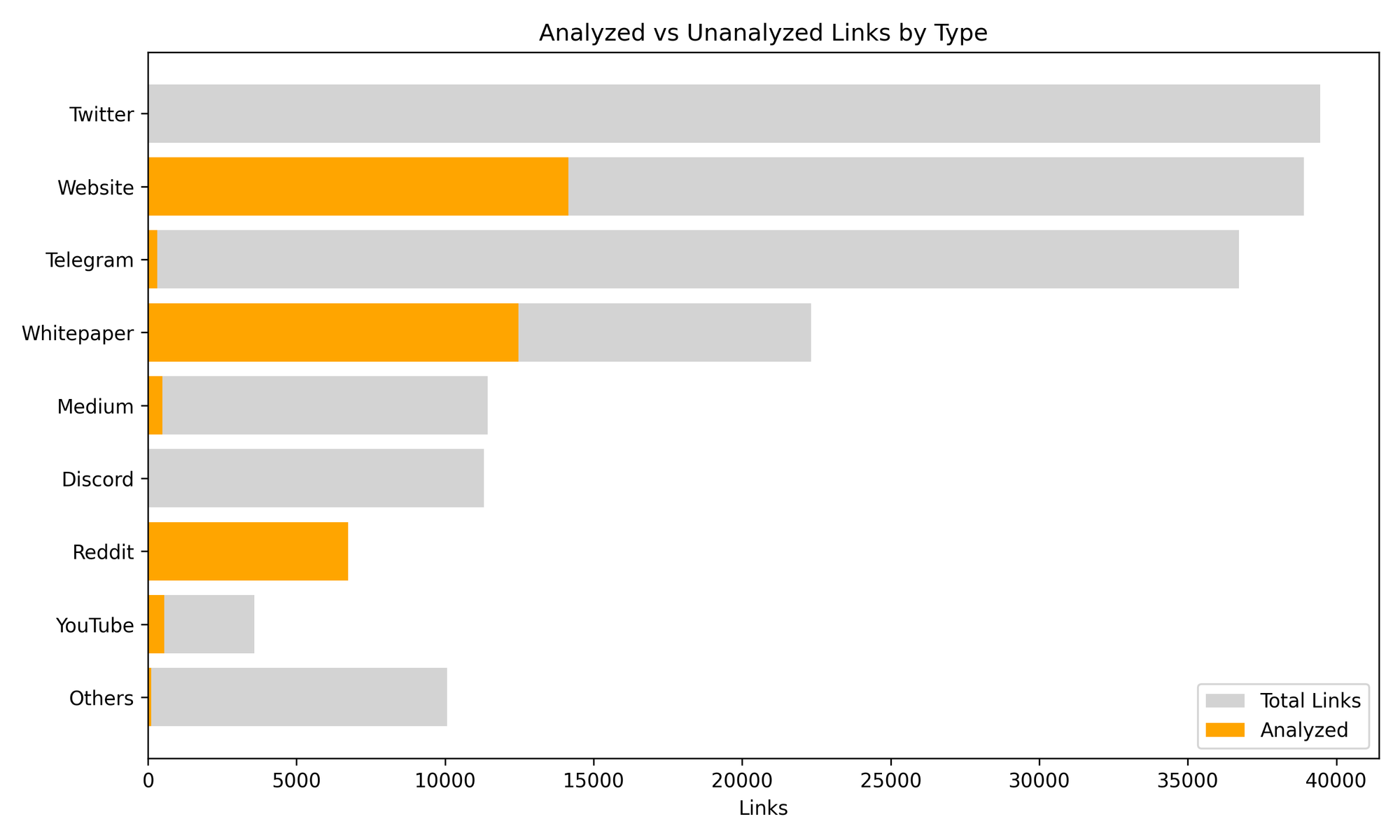
Reddit is 100% complete — while Twitter and Telegram remain high-priority for next-phase processing.
Local AI Integration: LLMs Powering the Analysis
Every project link is passed through Ollama-powered analysis layers.
The AI extracts structured data on:
- Tokenomics and team composition
- Risk profiles and compliance indicators
- Chain architecture, consensus, and roadmap summaries
The results flow into the link_content_analysis table, where over 17,000 LLM analyses have already been logged.
API Load & Latency Insights
Over 19,309 API calls have been made — balancing external data providers, AI workloads, and social integrations.
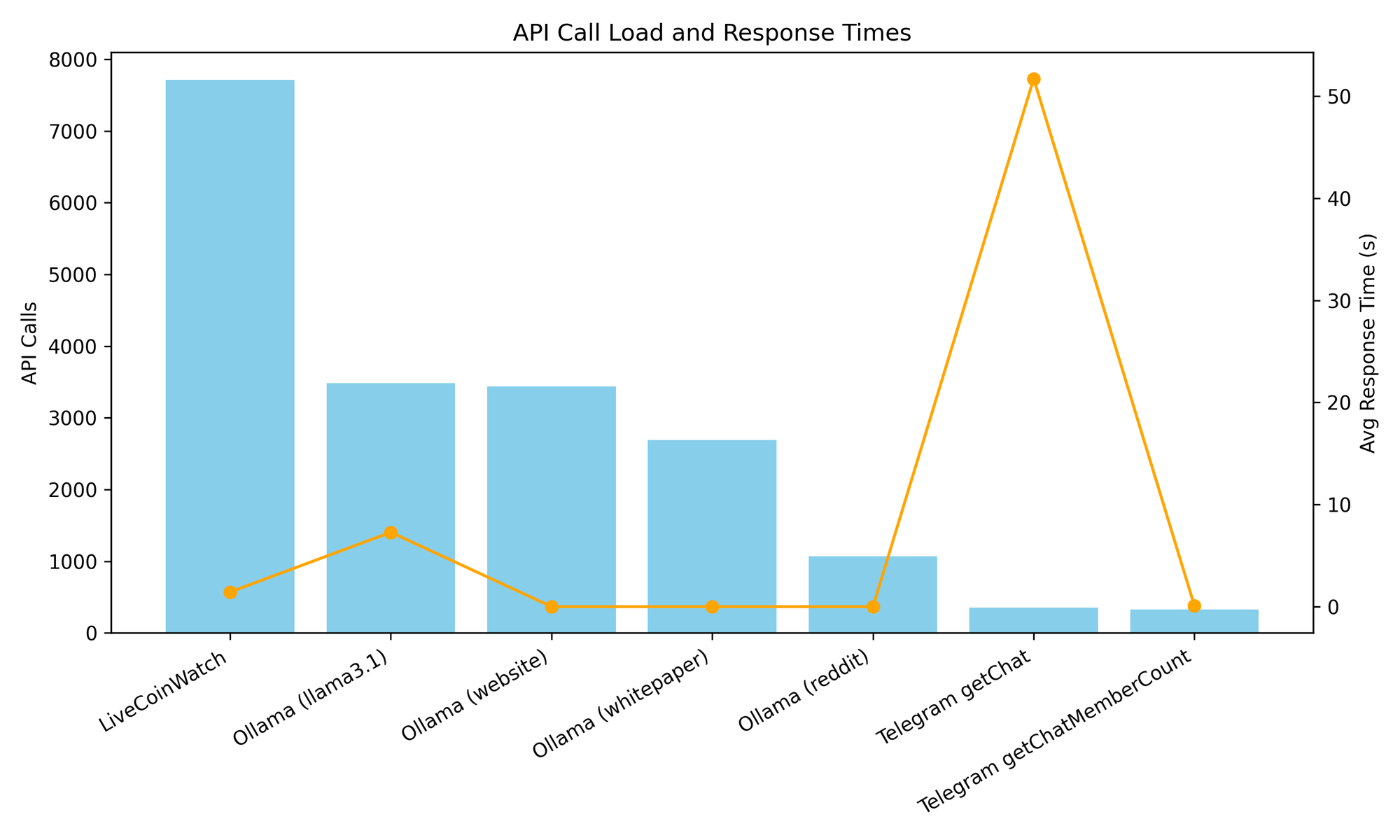
The graph above visualizes both total call volume and latency, showing that Telegram endpoints are the slowest (averaging 51s) while Ollama models process sub-second on local inference.
The Web Archival System: Preserving Blockchain History
Your archival layer is one of the project’s crown jewels — capturing the entire web presence of blockchain ecosystems.
Each snapshot is stored as a compressed .warc.gz file, making future replay possible via pywb.
| File | Size | Date |
|---|---|---|
graphlinq_io_20251027_203627_001.warc.gz | 1.29 MB | 2025-10-27 |
www_jr00t_com_20251027_201815_001.warc.gz | 127 KB | 2025-10-27 |
The current state of crawl jobs:
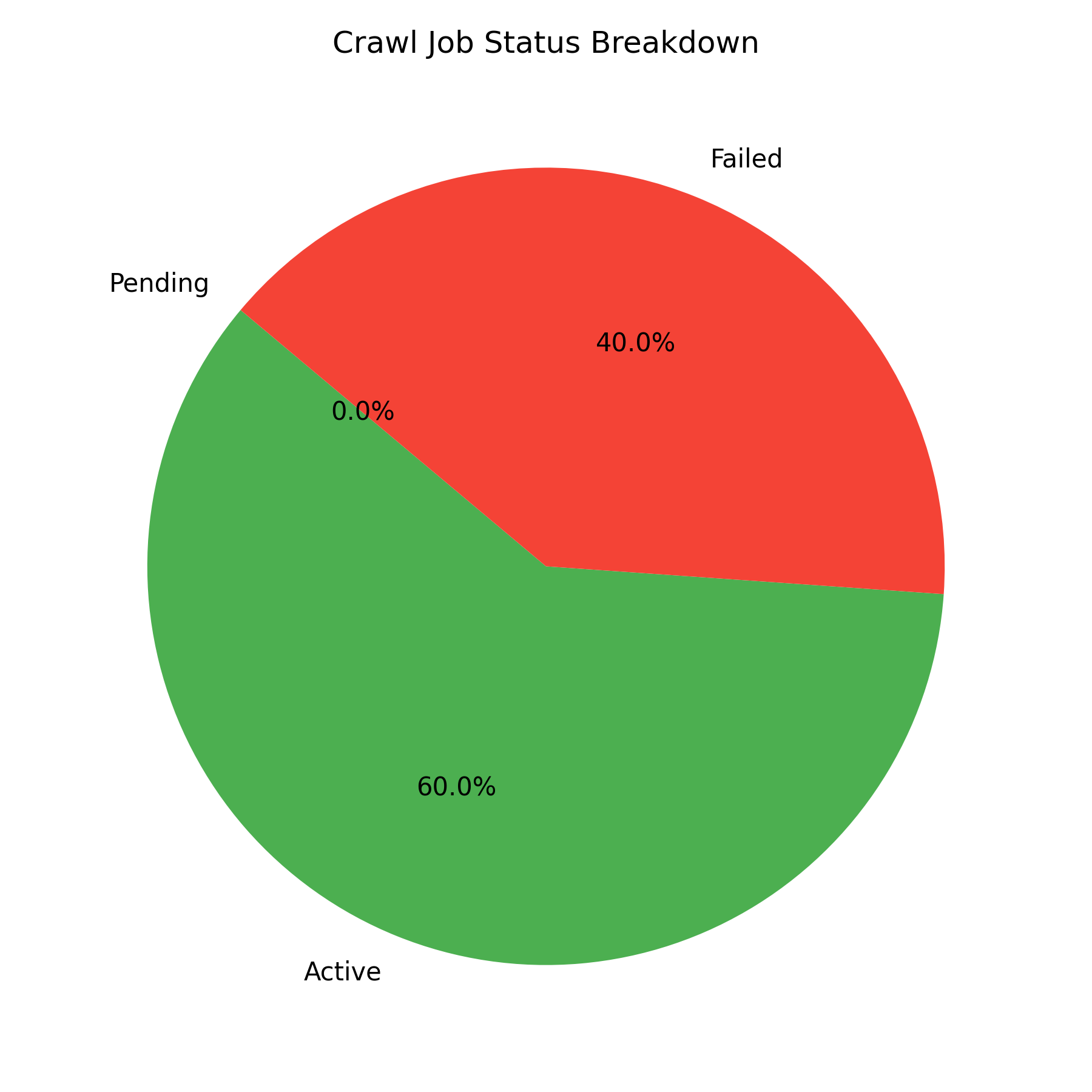
While the archival engine successfully creates WARC files, a next-phase fix will connect these with website_snapshots for full UI replay.
Redis Cache & System Health
Redis is configured for high performance with an LRU eviction policy, but it’s currently underutilized.
Even at 1 MB used out of 512 MB available, Redis remains primed for caching API and LLM results in upcoming pipeline optimizations.
The Strength Behind the System
Despite a few technical hurdles, the system demonstrates remarkable stability:
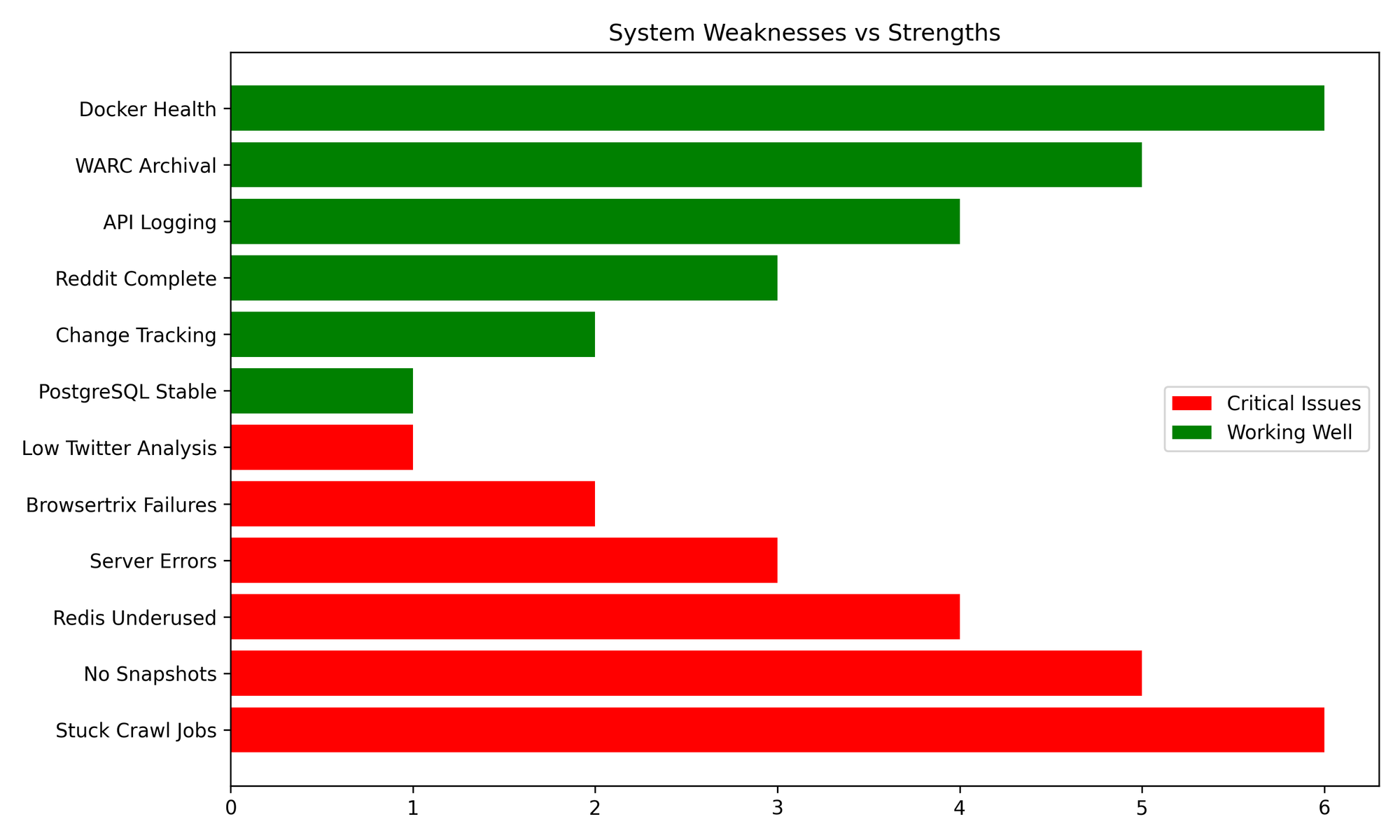
- PostgreSQL is rock-solid, tuned for hybrid OLAP/OLTP workloads
- All containers (Postgres, Redis, pgAdmin) are healthy
- WARC archival is functioning
- Change-tracking surpasses 2.5 million deltas logged
Meanwhile, most issues (stuck crawl jobs, Browsertrix timeouts, and low Twitter analysis) are easily fixable in the next cycle.
Roadmap: The Final Push to Full Automation
Here’s where theprogress stands for Phases 5–8:
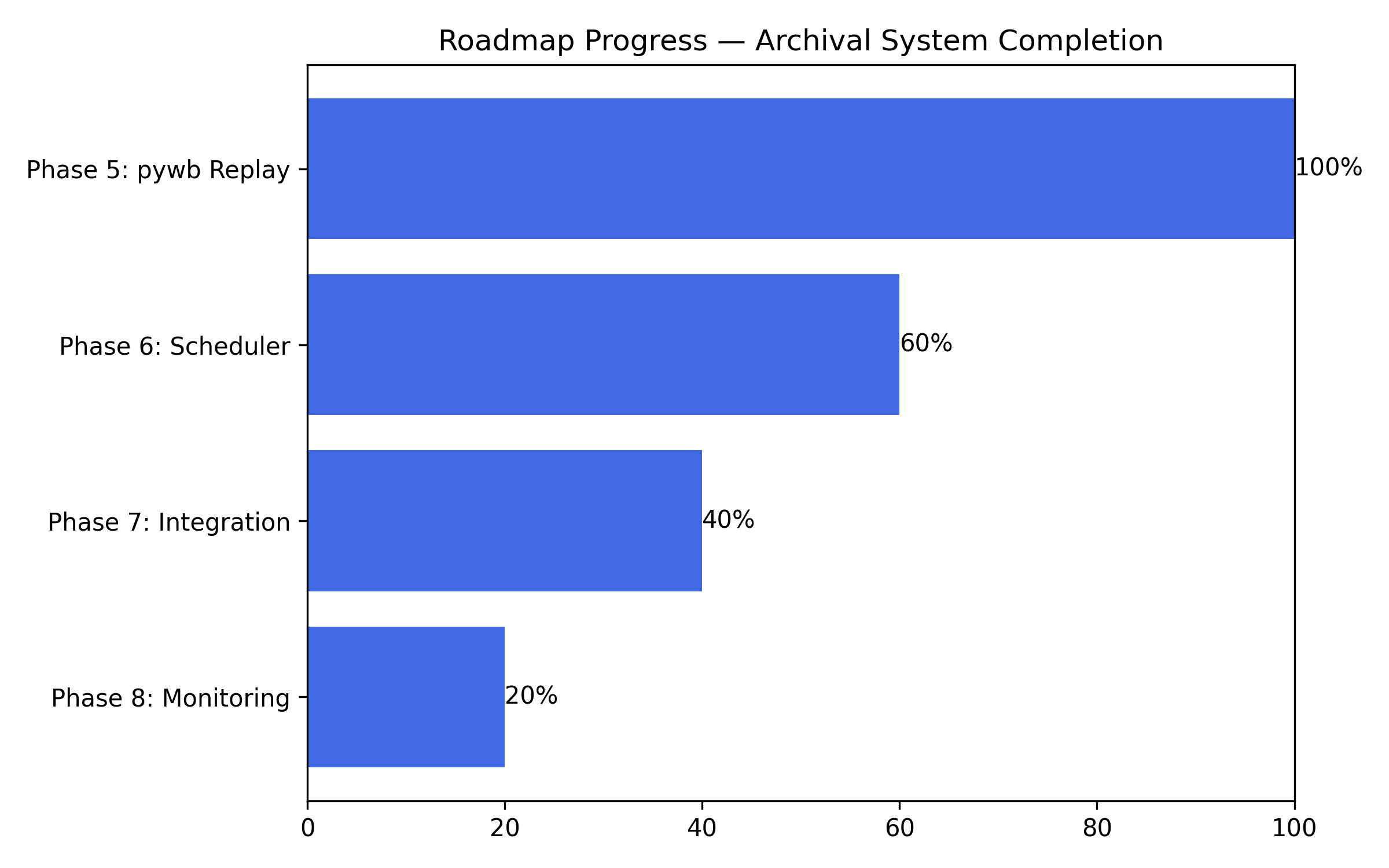
We are entering the automation era — where the entire data collection, analysis, and archival cycle will run hands-free.
- Phase 5: ✅ pywb Replay Integration
- Phase 6: ⚙️ APScheduler Automation
- Phase 7: 🔁 Pipeline Integration
- Phase 8: 📊 Monitoring Dashboard
The Bigger Picture
What’s emerging is a living neural network of the crypto web — continuously learning, archiving, and understanding.
For researchers, it’s a historical observatory.
For investors, it’s a source of verifiable intelligence.
For the crypto community, it’s digital preservation that can’t be faked or lost.
Final Thoughts
This project redefines what’s possible when blockchain data meets AI and archival science.
It’s not just tracking — it’s remembering.
Not just analyzing — it’s understanding.
With full automation and replay capabilities on the horizon, another step toward the goal of building the first self-sustaining crypto intelligence engine — a permanent record of the blockchain era in motion.